根据血清中微量元素含量用多变量分析辅助胃癌诊断
中国卫生统计 1999年第5期第16卷 论著摘要
作者:张晓滨 刘志红 任玉秋 任玉林 王孟才 徐刚
单位:张晓滨 刘志红 长春医学高等专科学校(130031);白城卫生学校 任玉秋;吉林大学化学系 任玉林;白求恩医科大学预防医学院 王孟才 徐刚
近年来,微量元素与肿瘤的关系越来越受到人们重视。大量研究结果都显示和证实了微量元素与肿癌的发生发展和防治均有密切关系。因此,很有可能根据癌症患者体内微量元素的含量,寻找一种有效的辅助诊断方法。本文根据血清中微量元素含量,应用逐步判别分析、主成分分析、系统聚类分析和逐步聚类分析等多变量统计方法,进行了胃癌辅助诊断的研究,用统计方法筛选出的几种元素在区分是否患胃癌上起着显著的作用。
实验部分
1.仪器和试剂 电感耦合等离子体原子发射光谱仪JARRELL-ASH800系列Mark-Ⅱ型。入射功率1.15千瓦,反射功率<5瓦。炬管为三同心石英管,冷却气流量17升/分氩气,载气流量0.5升/分,辅助气流量1升/分,样品提升量3毫升/分。观测高度工作线圈上方18毫米。积分时间35秒。元素铝、钙、镁、硼、磷和钛的定量测量下限为0.75μg/ml;钡、铅、锌为0.15μg/ml;铜、铬、铟、钼、锰、镍、钒、锆和钇为0.075μg/ml;铍、镉、钴、镧和锶为0.015μg/ml。用标准样品监控仪器工作状态,两组样品尽可能在相同条件下测定。
硝酸、高氯酸、Al、SrO、V2O5、Cd、CaCO3、MgO、Fe2O3和CuO等均符合分析要求。
2.样品及处理 对照组由31位正常人组成。无职业污染,无金属粉尘接触史,半年内无输血史,样品编号1~31。癌症患者组由16位胃癌患者组成。未经放疗、化疗而且有细胞学病理学诊断,样品编号为32~47,早晨5点至8点采空腹静脉血,注入离心管,离心30分钟。用移液管取血清放入小离心管,-20℃冻存。定量取≥1.000ml血清,移入聚四氟乙烯坩埚,加0.5ml高氯酸、5.0ml硝酸,加盖过夜。次日取下盖加热至120℃,蒸发至酸残余约1ml,冷却后移入10ml比色管,用去离子水定容到5.00ml。
3.数据处理 逐步聚类分析、系统聚类分析、主成分分析和逐步判别分析原理详见文献〔1,2〕。用本实验室编的程序处理血清样品中元素中含量数据,进行多变量统计分析。
结果与讨论
1.数据的基本统计
原始数据是容量为47(胃癌患者16人,正常人31人)的样本所测得的8种变量(元素含量)的值。分别按正常人组和胃癌患者组计算了均值、方差和标准差等基本统计量,见表1。表1中有些变量在两组中的均值相对差异较大,在统计分类中可能会起较大作用,但有些变量则相反。一般说来,一些非本质(不起区分作用)的变量的引用,有可能损害统计分类的效果。因此,有必要采用一种统计方法,对变量进行筛选。
表1 基本统计量
| 变量 |
正常人组(n=31) |
胃癌患者组(n=16) |
| 均数 |
方差 |
标准差 |
均数 |
方差 |
标准差 |
| Fe |
2.116 |
0.884 |
0.940 |
1.451 |
1.032 |
1.016 |
| Ca |
93.748 |
37.376 |
6.114 |
74.858 |
93.368 |
9.663 |
| Mg |
24.654 |
7.312 |
2.704 |
22.294 |
26.617 |
5.159 |
| Cu |
0.922 |
0.023 |
0.152 |
1.439 |
0.095 |
0.309 |
| Cr |
0.077 |
0.009 |
0.095 |
1.349 |
1.424 |
1.193 |
| P |
114.041 |
1302.871 |
36.095 |
129.987 |
1144.951 |
33.837 |
| Zn |
0.032 |
0.000 |
0.016 |
0.035 |
0.000 |
0.012 |
| Sr |
0.790 |
0.055 |
0.235 |
0.995 |
0.198 |
0.445 |
2.逐步判别分析
在筛选变量的基础上建立线性判别模型。筛选是通过F检验逐步进行的,每一步选取满足指定水平最显著的变量并剔除因新变量的引入而变得不显著的原引入的变量,直到既不能引入也不能剔除为止。
经过多次反复尝试,确定引入和剔除的F水平值均取为3(大致相当于90%以上的置信概率)为宜。经过6步筛选最后选定的变量为X2∶Ca,X4∶Cu,X5∶Cr,X6∶P,X8∶Sr。相应的两个判别函数为:
Y1=-88.33+1.79X2+8.28X4
+3.66X5+0.05X6-6.28X8
Y2=-73.82+1.36X2+24.13X4
+7.08X5+0.01X6+1.29X8
(1)
使用时,将一待查对象的有关元素含量值代入以上两个函数式,求得两个得分Y1和Y2。当Y2>Y1,判定为胃癌;当Y1>Y2时为正常。
对原样本中47人计算的得分和判定结果见表2。可以看出,判定结果与实际情况完全相符。
表2 逐步判别分析结果
| 样品
号 |
得分 |
判别 |
样品
号 |
得分 |
判别 |
| Y1 |
Y2 |
Y1 |
Y2 |
| 1 |
93.2752 |
79.8871 |
1 |
25 |
98.6872 |
89.8967 |
1 |
| 2 |
73.2533 |
63.6345 |
1 |
26 |
98.4287 |
88.6650 |
1 |
| 3 |
84.8277 |
75.6698 |
1 |
27 |
106.5887 |
80.9664 |
1 |
| 4 |
101.1684 |
89.6363 |
1 |
28 |
72.8739 |
62.3843 |
1 |
| 5 |
89.3592 |
80.9658 |
1 |
29 |
76.3612 |
68.1959 |
1 |
| 6 |
77.3037 |
67.8189 |
1 |
30 |
97.8881 |
89.9928 |
1 |
| 7 |
85.6081 |
79.0756 |
1 |
31 |
88.9032 |
82.6388 |
1 |
| 8 |
97.1582 |
83.5884 |
1 |
|
|
|
|
| 9 |
75.0208 |
69.1785 |
1 |
32 |
47.3219 |
64.4964 |
2 |
| 10 |
74.0662 |
64.7953 |
1 |
33 |
56.1050 |
65.3522 |
2 |
| 11 |
88.7873 |
77.0719 |
1 |
34 |
42.3795 |
48.5693 |
2 |
| 12 |
89.0079 |
75.0553 |
1 |
35 |
74.8800 |
83.7347 |
2 |
| 13 |
74.5047 |
65.3510 |
1 |
36 |
41.6471 |
51.4924 |
2 |
| 14 |
92.7756 |
83.0855 |
1 |
37 |
83.0212 |
102.4312 |
2 |
| 15 |
94.2717 |
85.1867 |
1 |
38 |
49.1405 |
62.5563 |
2 |
| 16 |
56.9614 |
50.2622 |
1 |
39 |
69.6035 |
83.3091 |
2 |
| 17 |
81.2944 |
66.0541 |
1 |
40 |
66.7232 |
80.2407 |
2 |
| 18 |
82.6178 |
69.5237 |
1 |
41 |
59.5697 |
76.0121 |
2 |
| 19 |
95.6207 |
83.8684 |
1 |
42 |
81.9818 |
84.3784 |
2 |
| 20 |
87.0252 |
71.4771 |
1 |
43 |
70.7360 |
84.1126 |
2 |
| 21 |
105.1190 |
87.7668 |
1 |
44 |
70.1072 |
76.8927 |
2 |
| 22 |
98.3384 |
89.0733 |
1 |
45 |
95.8661 |
100.5151 |
2 |
| 23 |
76.4473 |
74.4729 |
1 |
46 |
43.8592 |
56.0623 |
2 |
| 24 |
84.4995 |
75.3565 |
1 |
47 |
71.1656 |
72.9573 |
2 |
3.主成分分析
对数据分别用筛选后的5个变量和原始8个变量分别进行主成分分析。5个变量时,前两个主成分的累积贡献率为0.72;而8个变量时,前两个主成分的累积贡献率为0.54,见图1。两种情况都表明:两个主成分已经能很好地区分待查对象是否患有胃癌,其中用筛选后的5个变量时所得结果更好。值得注意的是,5个变量情况下,仅第一主成分就已能很好地区分。对一待查对象,将其各变量先中心化(变量的原始观测值与平均值之差)处理,然后将各变量的中心化值与该变量在第一主成分上的载荷值之积相加即计算出该待查对象在第一主成分上的得分。视其得分值的正负就能判定其是否无病。5个变量情况下,某一样本在中心化的第一主成分上的得分计算公式为:
S1=0.50(X2-87.32)-0.56(X4-1.10)
-0.49(X5-0.51)-0.37(X6-119.47)
-0.23(X8-0.86)
(2)
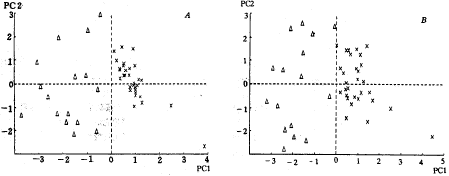
图例 ×:正常人Δ:胃癌患者
1 47个样本在前两个主成分上得分分布 (A)5个变量 (B)8个变量
4.系统聚类分析
将数据分别用5个变量和8个变量两种情况,用平方欧氏距离和Ward(类平均)类间距离计算所得的谱系图。从谱系图中也可看出,5个变量时,分得非常清楚并与事实完全一致。而8个变量进,分错的较多,这又说明了变量筛选的必要性。
5.逐步聚类分析
依据各分类对象在多维空间(维数由变量数决定)的位置和各类中心(即重心,亦称凝集点)间的距离进行分类的一种迭代方法。每步迭代都对各类中心进行调整并将分类对象按与各类中心的距离之远近进行归类,直到不变为止。
将数据分别按5个变量和8个变量进行逐步聚类分析。5个变量时,最后算得的两类样本在5维空间的两个中心的坐标分别为2.1160,93.7485,0.9219,0.0768,0.7905和1.4521,74.8581,1.4393,1.3495,0.9952。而8个变量时,两类样本在8维空间的两个中心的坐标分别为2.0808,93.5812,24.7331,0.9210,0.0795,114.6378,0.0319,0.8332和1.4819,73.9555,21.9683,1.4757,1.4286,129.7766,0.0355,0.9177。对于某一分类对象,比较它与第一中心与第二中心距离的相对大小,来判定是否患有胃癌,当距离1<距离2时,判定为正常;距离1>距离2时,判定为胃癌患者。由判断结果看出,5个变量的结果与实际完全相符,而8个变量的结果中47号胃癌患者被错分到另一类中。
结 论
1.根据血清中微量元素含量辅助诊断胃癌是可行的。
2.用统计方法对所测8种元素(变量)进行筛选是必要的。结果表明,Ca、Cu、Cr、P和Sr 5种元素在区分胃癌上起重要作用。
3.由(1)式给出的线性判别函数可作为胃癌的一种计量辅助诊断方法。
参考文献
1.Pedro J.M. et al.Application of several statistical classification techniques to the differentiation of whisky brands.J.Sci.Food Agric.,1988;45:347.
2.Hernandez C V.et al.Multivariate statistical analysis of gas chromatograms to differentiate cocoa masses by geographical origin and roasting conditions.Analyst,1994;119:1171.