第二节 现况调查的方法及种类
一、现况调查的方法
现况调查的方法有下列几种:
1.现场询问观察;
2.必要的检验;
3.统计分析。
上述三方面根据调查目的不同,其使用的方法亦各有所侧重。
二、现况调查的种类
(一)普查(census)
1.概念
普查是指在特定时间、对特定范围内的人群进行的全面调查。特定时间应该较短,甚至指某时点。一般为1~2天或1~2周,最长不宜超过2~3个月,特定范围可指地区或某种特征的人群。
2.调查的目的
(1)了解疾病的基本分布情况,如血吸虫病、高血压病、冠心病、食管癌的分布等;
(2)了解人群健康水平,如检查儿童的发育及营养状况;
(3)确定各项生理指标,如测定人群血液中红细胞数、测量人群血压值,以确定各项正常生理指标;
(4)早期发现并及时治疗病人,如宫颈癌的普查普治;
(5)描述某些可疑病因与疾病的联系,为寻找疾病的危险因素提供线索。
3.优缺点
优点:能提供疾病分布情况和流行因素或病因线索;通过普查能起到普及医学科学知识的作用;能发现人群中的全部病例,使其得到及时治疗。
缺点:由于工作量大难以作得细致,普查对象常难免有遗漏,不适于发病率很低的疾病;且此种调查耗人力物力大,成本高,只能获得患病率而不能获得发病率的资料。
4.普查工作中应注意的问题
(1)划定明确的普查范围。根据调查目的事先规定调查对象,并掌握各年龄组和性别的人口数;
(2)统一调查时间和期限。各调查组应大体上同时开始调查,并在一定期限内完成,普查时间不宜拖得太长,以免影响调调查结果的准确性,尤其对有时间波动的疾病;
(3)普查中使用的临床诊断标准和检测方法必须统一及固定,否则不同地区的患病率就不一样,而且资料之间无可比性;
(4)普查时要使漏查率尽量小,若漏查率高达30%,则该调查无代表性意义。一般要求应答率在95%以上。
(二)抽样调查(sampliingsurvey)
1.概念指从研究对象的总体中随机抽取有代表性的部分样本进行调查,从样本获得的信息来推断总体情况。它是以小测大,以部分估计总体特征的调查研究方法。
2.抽样调查的用途在流行病学研究和实际工作中具有重要地位。其用途如下:
(1)描述疾病的分布情况;
(2)研究影响健康的因素;
(3)研究卫生措施与预防、医疗措施及其效果;
(4)检查与衡量资料的质量;
(5)检验卫生标准;
(6)衡量一个国家或地方的卫生水平。
3.抽样调查的优缺点此法省时间、省人力和物力,调查范围小,调查工作容易做得细致。但设计、实施与资料分析比较复杂,重复和遗漏不易发现,不适用于变异太大的变量调查,小样本抽样调查对发病率很低的疾病收效不大,当须扩大样本到近于总体75%时,反不如直接普查。
4.抽样调查的原则和方法抽样调查设计和实施要遵循两个基本原则,即随机化和样本大小适当。常用随机化抽样方法有以下几种:
(1)单纯随机抽样(simple random sampling):按照一定技术程序以同等概率的抽样称简单随机抽样。随机化是随机抽样的极其重要的原则。
随机化需要一定的技术来实现,“随机”不等于随意或随便。从口袋里摸取有号码的纸团,结果不会得到满意的随机样本。抽签法或掷钱法在原则上虽是可取的,但实用的价值很小。
对于学生或战士等有组织的人员,可利用徽章号码分组。例如分3组时,可以3除以各人的号码数,按余数1、2、及0分为3组。如须分4组,则以4除号码数,按余数1、2、3及0分为4组。
有组织的人群亦可排成单行(不按身高为顺序),分2组时以“1~2报数”,分成2排;分3组时,“1~3报数”,余类推。
对没有组织人,可按出生月份的单双数分为2组。如须分为3组,可以1、2、3、4月出生的为第一组,5、6、7、8月为第二组,其余为第三组。
亦可将岁数加出生月份合得一数,用组数除之,余数为1的编入第一组,余数为2的编入第二组,余类推,无余数的以除数代余数。
使用随机数字表是比较简单而可靠的随机化方法。
用法举例:自500名学生中随机抽查100名在服驱虫药后排出的蛔虫数。自随机数表取出500个四位数记在学生卡片上,按随机数大小将卡片排列成序,以开头100张或末尾100张卡片为样本,或每5张卡片抽1张卡片为样本。
(2)系统抽样(systematic sampling):即按一定比例或一定间隔抽取调查单位的方法。首先确定抽样范围和样本含量,并给每一单位依次编号。然后确定抽样比,即确定每隔多少单位中抽取一个单位进入样本。至于究竟抽其中第几个,则须用随机方法决定,就是在从1至n个数中,随机选出一个数,把它作为起点,以后顺次每n个单位选一个单位进入样本。例如某乡有5000户,二万人口,今欲抽查1/5的人口可用系统抽样,每5户抽一户,抽到的户每个成员都要调查。决定起点应是随机的。
用系统抽样得到的样本,其代表性较有保证,因为构成样本的单位是从分布在总体各个部分的单元中按一定比例抽取出来的。但是必须事先对总体的结构有所了解,才能最恰当地应用系统抽样。
(3)分层抽样(stratified sampling):把总体按若干标志或特征(例如性别、年龄、居住条件、文化水平等)分成若干层,然后在每层中抽取调查单位,再合成为总体的一个样本,这种方法称分层随机抽样。具体抽样方法可用简单随机抽样法或系统抽样法。由于各层次之间的差异已被排除,其抽样误差较其他抽样为小,代表性亦较好。各层若按一定比例抽样,则称按比例分层抽样。但各层内变量的变异很大时,分层抽样的益处不大。例如按年龄分层,没有考虑各层男女比例的差异很大,如果差异很大,就不能算好的分层。层间差异大,层内差异小最适合分层抽样。
(4)整群抽样(cluster sampling):就是从总体中随机抽取若干群对象(如学校、工厂、村庄等),对整群内所有调查单位进行调查,称之整群抽样。例如调查20所小学约10000名小学生某疾病的现患率,现拟抽查1/5的数量,如用单纯随机抽样方法抽到对象分散在各所小学,调查很不方便;但若随机抽取4所小学,抽到的学校学生全部调查,则方便多了。本法易被群众接受。整群抽样的缺点是抽样误差较大。
(5)多级抽样(multistage sampling):是进行大规模调查时常用的一种抽样方法。实质上是上述抽样方法的综合运用。从总体中先抽取范围较大的单元,称为一级抽样单元(例如省、自治区、直辖市)再从每个抽中的一级单元中抽取范围较小的二级单元(县或街道),最后抽取其中部分范围更小的三级单元(村或居委会)作调查单位。在大规模调查时可按行政区域逐级进行。我国进行的慢性病大规模现况调查大多采用此方法。
5.抽样调查样本大上的估计在抽样调查时,样本过大可造成浪费,且由于工作量过大,不能保证调查质量而使结果出现偏倚。样本过小则没有代表性。样本大小取决于:
(1)如果研究单位之间的变异较大,样本则要大些,如其间均衡性较好,则样本可以小些;
(2)在调查的人群中,欲调查某疾病的现患率,如现患率低,则样本量要大。反之,样本可小些;
(3)调查要求的精确度高些,样本量就要大。反之,样本量不必过大;
(4)把握度的大小(即1-β),如把握度要求高,则样本量适当大些,反之,则可小些。
一般样本大小可用下列公式计算:
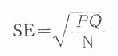
式中SE=标准误,P=某病的现患率,Q=1-P,N为样本数。
根据上述公式,可得到下列简便公式:
N=400×Q/P
式中N=样本数,P=预期现患率或感染率,Q=1-P。
本公式要求允许误差为0.1P,95%可信限水平t=2。样本的感染率P与总体感染率P之间有差异d。P-p=±d=±t×SE。
SE=d/t。0.05水平,自由度为无限大时,t约为2。

令d为=0.1P
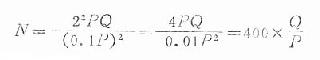
若允许误差d=0.15P,则
N=178×Q/P
同理,d=0.2P时,N=100×Q/P
按此三公式,表28-1可作为调查样本大小之参考。
计算实例:某工厂有职工一万余人,现需估计全体职工携带乙型肝炎表面抗原情况。该地区乙型肝炎表面抗原携带率约10%。现采用抽样调查,要求允许误差为0.15P,计算需抽样调查人数。
d=0.15P
N=178×0.9/0.1=1602人
不同允许误差,调查人数不同。
表28-1是用上式计算出来的样本大小,可参考使用。但当流行率或阳性率明显小于10%,此式不适用。
表28-1 按不同预期阳性率和允许误差时的样本大小
| 预期阳性率 | 允许误差 | ||
| 0.1P | 0.15P | 0.2P | |
| 0.05 | 7600 | 3382 | 1900 |
| 0.075 | 4933 | 2193 | 1328 |
| 0.10 | 3600 | 1602 | 900 |
| 0.15 | 2264 | 1009 | 566 |
| 0.20 | 1600 | 712 | 400 |
| 0.25 | 1200 | 533 | 300 |
| 0.30 | 930 | 415 | 233 |
| 0.35 | 743 | 330 | 186 |
| 0.40 | 600 | 267 | 150 |
-
《预防医学》 中的相关章节:
……
第三节 研究的对象
第四节 资料收集
第五节 流行病学发展近况
第二十八章 现况调查
第一节 概述
第二节 现况调查的方法及种类(当前页)
第三节 现况调查资料整理分析和结果解释
第五节 现况调查中的偏倚及其防止
第二十九章 病例对照研究
第一节 概念及结构模式
……